Technical localization challenges and how to solve them
Codeglue's Thomas Jongman details common issues you can encounter when localizing Japanese games into English

Stranger of Sword City Revisited (SoSCR) and Saviors of Sapphire Wings (SoSW) are two dungeon crawling JRPGs that have had prior releases for the PlayStation Vita, in 2016 and 2019 respectively.
Late in 2019, NIS America approached us to discuss porting these two games to the Nintendo Switch and PC. This article outlines the technical localization challenges that were found in the two games and how we approached solving them. It does not cover the actual translation of text found in both games, which was handled by NIS America.
The original situation
The original Vita release of SoSCR already was an English localized release, so you might be wondering what the difficulty was with creating the English localized versions for the new platforms?
Well the Japanese release and English release of this game were two entirely separate SKUs, featuring only the Japanese or English text and no option in-game to switch between the two languages. This was something that had to be implemented for a global release.
As for SoSW, the original game had only seen a Japanese release under the name 蒼き翼の シュバリエ (Aoki Tsubasa no Chevalier), there was no English text or release whatsoever.
Japanese text encoding
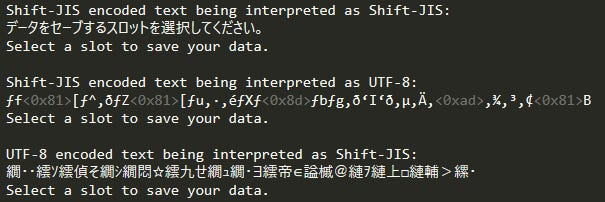
Something that applies to most Japanese games is that text and source code tends to be encoded using the Shift-JIS encoding rather than the UTF-8 encoding that's much more commonly used in software. This can lead to syntax errors when the compiler interprets the source code as another encoding and encounters unexpected characters. Our solution to this was to create a script that converts the source code to UTF-8.
There's a catch to doing this though. If the source code contains hardcoded strings then those will be converted as well, which will cause havok when these strings are then passed to systems that are still expecting the Shift-JIS encoding. Luckily for us, SoSCR and SoSW didn't have any.
Text data from assets
In both games the text that's displayed to the player was spread out over multiple different files and file types. The separation being determined by content creation tools that determine which feature or screen ends up showing the text in game.
So if you ever find yourself working on porting a game, never assume that you've found all the text once you've stumbled across the largest file containing text data. A best practice is to search through all files with a text editor or custom script to check for common words and phrases. This will help you in discovering all files containing text in the project. Just be sure to also check the binary files!
Never assume that you've found all the text once you've stumbled across the largest file containing text data
For this project the text was split into:
- Text that is only shown in the UI.
- Text that is spoken by the characters.
- Text that is associated with objects, usually referred to as "type data" (items, spells, quests, etc.).
- Text that is shown in an in-game manual.
The source of these different types of text were Excel spreadsheets. These Excel spreadsheets were then used as the input for a series of custom tools, outputting different files such as C++ headers, plain text files or custom binary formats. We had to take all these different sources of text data into account when working on the localization systems for porting the games.
Localization solutions for SoSCR
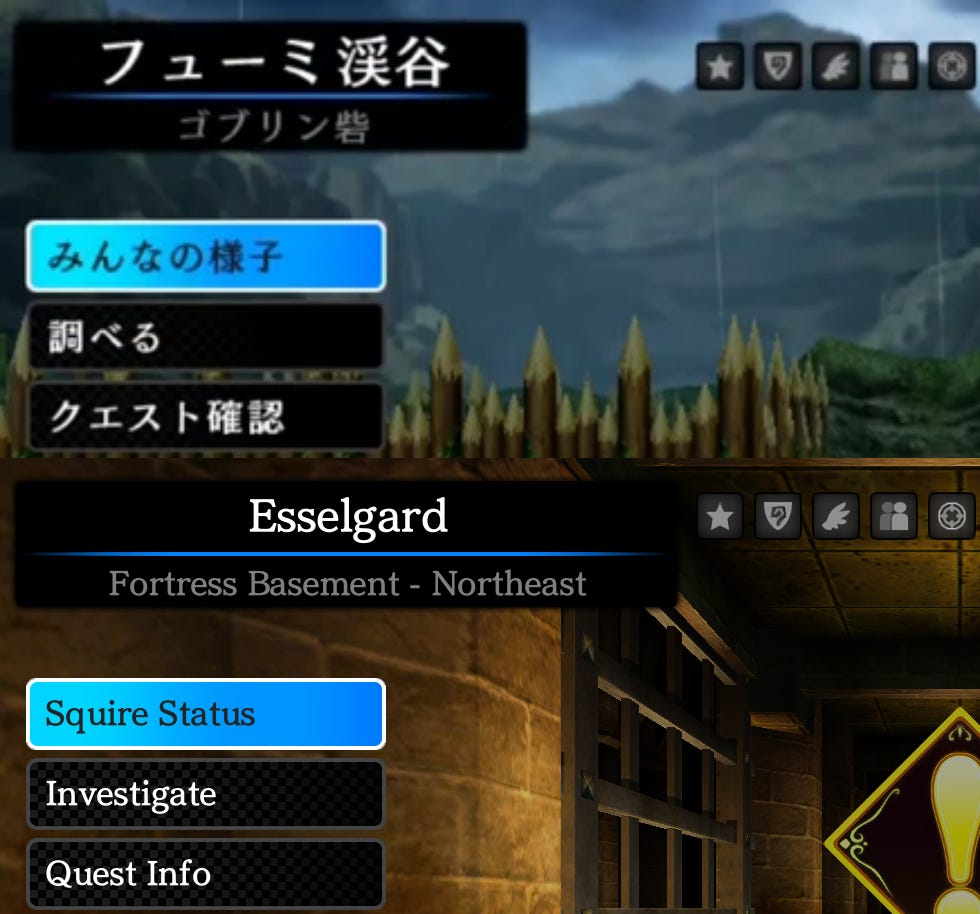
For SoSCR, an English and Japanese version of these texts already existed and the solution for making the game support both languages at the same time was to create the compiled assets for both languages and loading the correct file based on the language setting. So for example, before we had a single "dialog.dat" file and afterwards we would have two files named "dialog_en.dat" and "dialog_jp.dat".
This wasn't the only solution to the problem: there was also the option of interleaving both languages in the same file. This option will end up costing less hard drive space as there's only one file, but does require tooling that generates the file to change and the code that loads it. We found that this was the less ideal solution, as JRPGs like SoSCR have a lot of different kinds of type data; the amount of code that needed to be adapted was simply too great a risk. So in the end we went with the first solution.
One case in which this split file approach didn't work was with the custom script file used for dialog. This file contained the text spoken by the characters as well as game specific commands such as giving the party a key item or starting a new quest. It was because of this that the file couldn't be reloaded while in-game. Trying to do so would make references to internal data structures invalid and cause the game to crash. The tool that created this custom script file lets you pick whether you want to use the English or the Japanese text in the generated file. It then uses the text IDs from the script source files to include which line of text to insert in the output file.
The solution we went with here was to decouple the language substitution the script tool does to the text files. So now the custom script file only contains the text IDs and does not insert the final text, instead the game does this lookup in the English or Japanese dialog text based on the language setting.
Localization solutions for SoSW
In the case of SoSW, making a dual language version was more complicated. It also has a custom script file like SoSCR, but unlike the first game the tool that generates the custom script file does not perform the text substitution using text IDs. All the spoken text is present directly in the custom script file source files.
Files like this obviously can't be handed to a localization team as they contain lines of code used to select the text required. So the problem we faced was the need to extract these strings into an Excel sheet so the workflow would be the same as that of SoSCR.
To do this we created a Python script that iterated over the custom script file, gathering all the text and at the same time replacing said text with an ID so it could be used to look up an English or Japanese string at runtime instead.
Because of the English text generally taking up more space than Japanese, some UI elements needed to be resized
Another source of text that caused problems was the text from type data. These tend to have short names for their identification and since Japanese requires fewer characters for these words the members of the associated type data structures weren't long enough to fit in the English text.
At first we tried to increase the byte size of these fields both in the game and the tool that compiled the type data assets. Unfortunately the tool proved to be very fragile. So we ended up bypassing the problem by exporting the English type data text to an entirely new file and referring to it from the game only if the language was set to English. Although this is not an ideal solution it is one without a drawback for the game itself so we were still happy with it.
One of the last issues we tackled was that, because of the English text generally taking up more space than Japanese, some UI elements needed to be resized in order to accommodate it. Shrinking the text is also an option here but tends to look rather bad, especially in cases where multiples of the same kind of text is on screen such as in a list.
Lastly, there were also some images with text and videos with text. The solution here was to simply use the multiple files approach again and load them based on the language.
In the end every project is a learning opportunity with its own challenges to overcome. This was the first time we ported a dungeon crawler RPG to modern platforms and we have learned a lot from it.
Thomas Jongman was one of the leads on Codeglue's Stranger of Sword City Revisited/Saviors of Sapphire Wings project and has been a game programmer at the company since 2019.